RubiPython is a feature within Code Fusion on the Rubiscape platform to write your code in the Python programming language for building models.
You can use the RubiPython node as a stand-alone node, or you can connect it to your Reader node (dataset) or other algorithm nodes. You can connect multiple predecessors or preceding tasks to a single RubiPython node.
Each predecessor task and all the columns present in the task appear on the RubiPython configuration page. You can differentiate each predecessor task and its columns by their names. This feature is useful when you have large data to combine or split and perform different actions on it.
Writing Custom Code using RubiPython
To write your custom code using RubiPython, follow the steps given below.
- Create your algorithm flow. Refer to Building Algorithm Flow in a Workbook Canvas.
- Drag and drop RubiPython on your workbook canvas.

Notes:
- You can connect multiple predecessor nodes to RubiPython. The output of all the predecessors is available for your use in the RubiPython node.
- If you connect the dataset to RubiPython, the dataset fields are available as input to RubiPython.
- If you connect the algorithm to RubiPython, the columns in the resultant data are available as input to RubiPython.
Connect required nodes to RubiPython in your algorithm flow.
- Select RubiPython and in the Properties pane, click Configure.
The RubiPython configuration page is displayed.
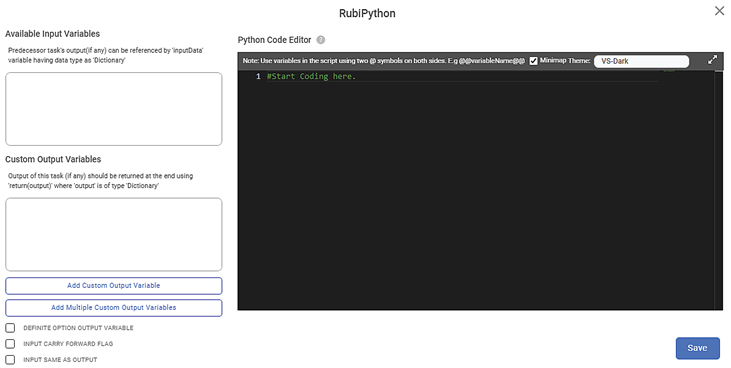
The fields/icons on the RubiPython configuration page are described in the table below.
Icon/Field
Description
Available Input Variables
- It displays the features (columns) present in the preceding task’s output. These features are stored in a variable named
inputData, which is of dictionary data type. Dictionary is a data type that contains name-value pairs.
- You can access the features in the
inputDatavariable and process them to create your custom variables. - You can access all the preceding task names, the features (columns) present in each task, and the index of each row in the task in the
inputDatavariable. - You can access all the preceding task names in the variable named
inputData.keys(), which is of dictionary data type. - You can access all the features (columns) present in a particular preceding task and the index of each row in the
inputData[‘dataset_ name’]variable. - You can access a single feature (column) from the features present in a particular preceding task and the index of each row in the
inputData[‘<dataset_ name>’][‘<column_name>’]variable.
Custom Output Variables
It displays a list of output variables created by you. These variables are stored in the form of a Dictionary.
Add Custom Output Variable
It helps you create your custom output variable from the existing variables (Features of the dataset). Refer to Creating Custom Output Variable.
Add Multiple Custom Output Variable
It helps you create multiple custom output variables from the existing variables (Features of the dataset). Refer to Creating Multiple Custom Output Variables.
DEFINITE OPTION OUTPUT VARIABLE
- If selected, only the Custom Output Variables are passed on to the successor node.
- If multiple predecessors are connected to the RubiPython component, this flag is false (not selected) by default. You can select it as per your requirements.
INPUT CARRY FORWARD FLAG
- If selected, the variables received as input from RubiPython’s predecessor tasks are passed on to the successor task, not otherwise.
Note: This is possible only when a single predecessor is connected to RubiPython, not when multiple predecessors are connected to RubiPython. - This flag is disabled when multiple predecessors are connected to RubiPython. So, the input variables do not appear on the Data page when you explore RubiPython.
- Upon exploring RubiPython, you can view the custom output variables for RubiPython in its Data page if you have created the variables.
INPUT SAME AS OUTPUT
- If selected, the input to the RubiPython node is passed on to the successor task; not otherwise.
- If multiple predecessors are connected to the RubiPython component, this flag is false (not selected) by default. You can select it as per your requirements.
Python Code Editor
The Python Code Editor helps you to add your customized Python code. Refer to Using Python Code Editor.
TRAINING REQUIRED
Functionality is coming soon.
Minimap - It is a small, scaled version of code editor window.
- If selected, shows the overview of entire code area in top right corner of code editor window.
Theme - It helps you to customize the code editor theme.
- Following theme options are provided:
- VS-Dark
- VS-Light
- High Contrast-Dark
- High Contrast-Light

It helps you to maximize the Code Editor page.

It saves the changes, closes the configuration page, and returns you to the workbook canvas.
- It displays the features (columns) present in the preceding task’s output. These features are stored in a variable named
- Write your Python code in the Python Code Editor. Refer to Using Python Code Editor.
- After completing, click Save.
- To execute the code, Run the RubiPython node.
After successful execution, a confirmation message is displayed. You can view the output of the custom component under View Log > Custom Component Log.
Using Python Code Editor
In the Python Code Editor, you can add your Python code.
- The input variables are stored in the form of a Dictionary data type inputData.
- Similarly, newly created variables are stored in another Dictionary type variable output.
- To use new variables in your code, you first need to create them. Refer to Creating Custom Output Variable.
- To print to the console, use
print2log(). - You can use variables declared at the workbook/workflow level in your Python code. Refer to Using Variables in RubiPython.
A sample Python code is shown in the image below.
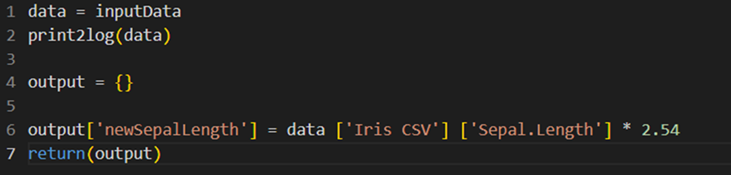
The table below explains the above code snippet.
Line of Code | Result |
| It creates a copy of |
| It prints the contents of |
| It creates a new variable named ‘output’ of type dictionary. |
| It assigns the value of Sepal.Length of Iris CSV dataset multiplied by 2.54 to column |
Notes: |
|
A sample Python code to access predecessor tasks is shown in the image below.
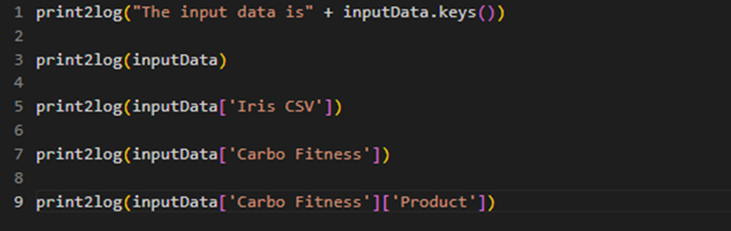
The table below explains the above code snippet.
Line of Code | Result |
| It prints all the predecessor task names referenced by inputData to the console log or custom component log as a dictionary. |
| It prints the contents (predecessor task names, column names, and index) of inputData to the console log or custom component log. |
| It prints the contents (column names and index) of the predecessor task to the console log or custom component log. |
| It prints the contents (column name and index) of a particular column of the predecessor task to the console log or custom component log. |
Creating Custom Output Variable
To create custom variable in your RubiPython code, follow the steps given below.
- On the RubiPython page, click Add Custom Output Variable.
Create Custom Variable page is displayed. - Enter a Name for your output variable.
Select the type of your output variable from the Variable Type drop-down. The options are Categorical, Numerical, Interval, and Textual.
Note:
Ensure the data type of the newly created output variable matches the data type of the corresponding input variable. If the variable types do not match, the application gives an error when running the algorithm flow. - Select data type of the output variable from the Data Type drop-down. The options are Integer, Textual, Float, and Boolean.
- Click Create.
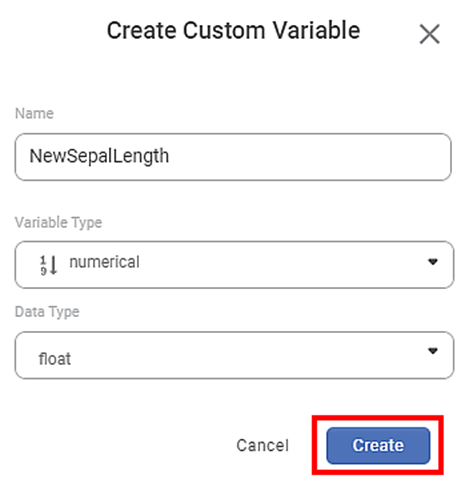
The output variable is created and is added to the Custom Output Variables list.
Creating Multiple Custom Output Variables
You can create multiple custom output variables by providing a JSON string.
To create multiple custom output variables in your RubiPython code, follow the steps given below.
- On the RubiPython configuration page, click Add Multiple Custom Output Variable.
Create Custom Variable page is displayed. Enter JSON strings in the following format –
<Variable1 Name>, <Variable Type>, <Data Type>; <Variable2 Name>, <Variable Type>, <Data Type>; …<VariableN Name>, <Variable Type>, <Data Type>.Note:
Individual elements of the string should be separated by comma (,) and the strings should be separated by a semicolon (;).
For example, to add the variables Name and Age of type Text and Integer respectively, the string would be – Name, Textual, Textual; Age, Numerical, Integer.
Click Validate to validate the string.
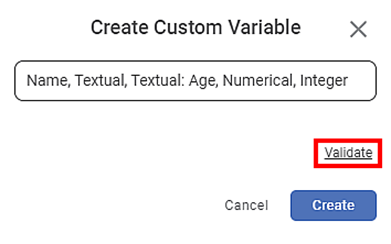
If the string is valid, a confirmation message is displayed. If the string is invalid, the application gives an error message. You can rectify the errors and try again.
After you make sure the string is valid, Click Create.
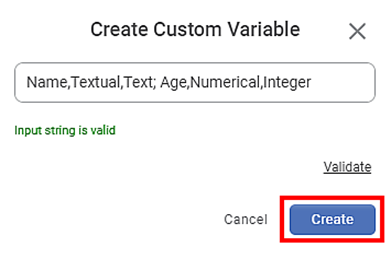
The specified output variables are created and are added to the Custom Output Variables list.
Notes: |
|
Writing Custom Functions to Access Data using RubiPython
You can use custom functions in RubiPython to
- read a dataset without connecting to the Reader node
- write data to a file or an RDBMS table without using the Writer functionality
- upload file to cloud storage
- download file from cloud storage
The following sections explain these custom functions.
Reading Data from File
A sample Python code to read data from file is shown in the image below.

The table below explains the above code snippet.
Line of Code | Result |
| This custom function checks the type of the dataset (Excel, CSV, and Text) and accordingly reads the dataset and returns it as an output of the function of dictionary type. |
| Prints the Reader output data as a dictionary to the console log or custom component log. |
Note: | In the |
Writing Data to File
A sample Python code to write data to file is shown in the image below.

In the above code, the writeDataToFile custom function is used to append a row to the selected Carbo Fitness file (dataset).
dataToWritestores the output data of the type dictionary to write to a file.writeDataToFile(dataToWrite,“action”,“delimiter”,“datasetName”)custom function appends or overwrites the output data to the selected file (Excel, CSV, or Text datasets).
The table below describes the writeDataToFile function and parameters.
Function | Parameter | Remarks |
|
| — |
| It is of type String, and values can be overwrite and append. | |
| It is of type String, and values can be – “,” / “|” / “ ” / “ ” (comma, pipe, tab, and space). | |
| It is of type String. |
Another example of reading and writing to a file is shown below.

Reading Data from Table
You can use getReaderData to read the data from RDBMS Table.

In the above code,
getReaderData(“datasetName”,“subdatasetName”)custom function checks the type of the dataset and accordingly reads the dataset from the Reader and returns it as an output of the function of type dictionary.print2log(dataToWrite)prints the output data as dictionary to the console log or custom component log.Note:
In the getReaderDatacustom function, the dataset and the sub-dataset names are the same for all datasets except for RDBMS datasets. In case of RDBMS datasets, sub-dataset name is the name of the table added in the RDBMS dataset.
Writing Data to Table
Similarly, you can use writeDataToTable to write the data into RDBMS Table.

The table below describes the writeDataToTable function and parameters.
Function | Parameters | Remarks |
|
| — |
|
| |
| It is of type String. | |
| It is of type String. | |
|
| |
|
|
Notes: |
|
Writing custom function for image dataset using RubiPython
To read the image data using custom function from Rubipython follow the steps given below.
- Select an image dataset from the reader section in the task pane.
- Drag and drop RubiPython on your workbook canvas.
- Connect required nodes to RubiPython.
- Select RubiPython and, in the Properties pane, click Configure
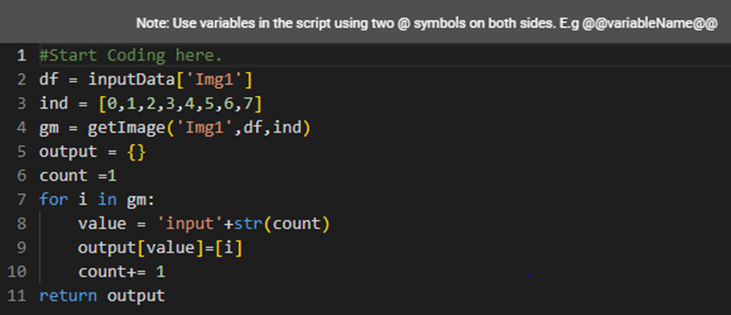
Line of Code | Result |
| It creates a copy of inputData with the name df. |
| It declares a variable containing the list of index values. |
| It gives image objects in n-dimensional arrays. |
| It creates a new variable named ‘output’ of the type dictionary. |
| We initialize the count from 1. |
| It defines a ‘for’ loop for the values in gm. |
| It combines the input and count in strings. |
| It assigns the n-dimensional arrays of the image to the value variable. |
| It increases the count by 1. |
| It returns the output. |
Reading the image data using metaImage function
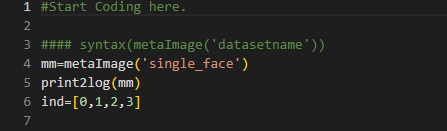
Another way to read the image dataset is by using the ‘metaImage’ function. In rubipython ‘metaImage’ function reads the image dataset without connecting to the rubipython node. Its syntax is (metaImage('datasetname')).
Create a custom output variable to store the images. For creating custom output variables, refer to Creating Multiple Custom Output Variables.
After successfully running the Rubipython node, we select the face verification algorithm.

In it, we select the source image and target image.
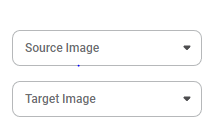
And then run the algorithm.
It identifies whether the face in the source image and target image are the same or not.
Uploading File to Cloud Storage
RubiPython provides a custom function to upload files to S3 server. The code syntax to upload a file to cloud storage is shown below.
|
Downloading File from Cloud Storage
RubiPython provides a custom function to download files stored on S3 server. The code syntax to download a file from cloud storage is shown below.
|
If the downloaded file is a CSV, you can use the below syntax to read the contents of the downloaded file.
|
Using Variables in RubiPython
The variables defined at the workbook/workflow level can be used in the RubiPython custom component.
To use a user-defined variable in RubiPython, follow the steps given below.
- Create your algorithm flow. Refer to Building Algorithm Flow in a Workbook Canvas.
- Drag and drop RubiPython on your workbook canvas.
- If required, connect other nodes to the RubiPython node in your algorithm flow.
- Select RubiPython and in the Properties pane, click Configure.
The configuration page is displayed. - Write the code in the RubiPython Code Editor. Refer to Writing Custom Code using RubiPython.
- To use a workbook/workflow level variable in the code statements, use @@ symbols before and after the variable name.
For example, if the variable name is var1, you can use it in RubiPython as @@var1@@.
A sample RubiPython code containing a user-defined variable is shown in the figure below.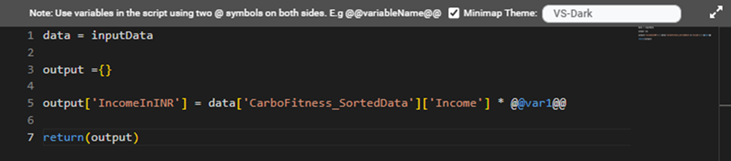
Publishing RubiPython Code
You can publish the RubiPython code from a workbook and reuse it in another workbook or workflow. This feature is similar to publishing models in RubiStudio.
To publish RubiPython code, follow the steps given below.
- Write the RubiPython code as required. Refer to Writing Custom Code using RubiPython.
- Run the RubiPython node.
- After the node is successfully executed, select the node, click the vertical ellipsis (
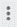 ), and click Publish code.
), and click Publish code.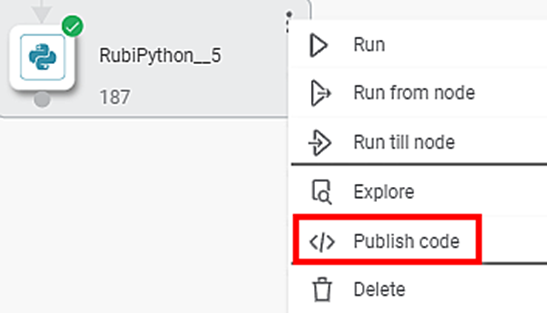
After the code is successfully published, a confirmation message is displayed. This code is listed under Reusable Codes on the Rubiscape Home page.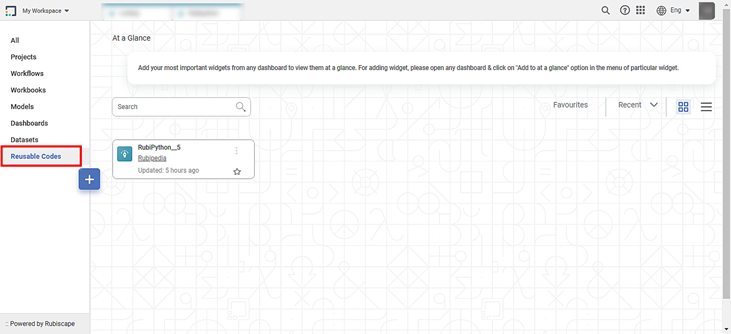
Notes: |
|
Reusing RubiPython Code
The published RubiPython code is available for reuse in workbooks and workflows in the same workspace.
To reuse a published code, follow the steps given below.
- Open the workbook or create a workbook. Refer to Opening a Workbook and Creating a Workbook.
- Click Reusable Codes under Code Fusion in rubistudio in the Task Pane.
The available reusable codes are displayed as shown in the figure below.
- Double-click or drag-and-drop the node on the workbook canvas.
- To run the code, select the node, click the vertical ellipsis (), and click Run.
After the node executes successfully, a confirmation message is displayed.
Table of contents