Combined Data Cleansing | |||
Description |
| ||
Why to use | Data Preprocessing to
| ||
When to use | When you want to remove any deformity or anomaly in the data. | When not to use | When the data is clean and already preprocessed |
Prerequisites | - | ||
Input | Unclean data | Output | Cleansed Data |
Statistical Methods used | - | Limitations | - |
Combined Data Cleansing is located under Model Studio ( ![]() ) in Data Preparation, in the left task pane. Use the drag-and-drop method to use the algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
) in Data Preparation, in the left task pane. Use the drag-and-drop method to use the algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
Refer to Properties of Combined Data Cleansing.
Properties of Combined Data Cleansing
The properties of Combined Data Cleansing are as shown below.
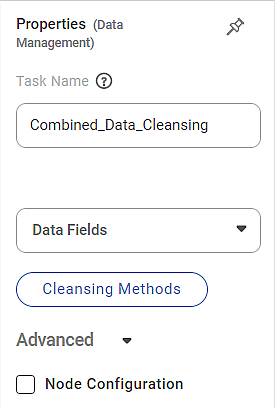
The table below describes different fields present in the properties of Combined Data Cleansing.
Field | Description | Remark |
|---|---|---|
Task Name | It is the name of the task selected on the workbook canvas. |
|
Data Fields | It allows you to select the columns on which you want to apply the cleansing methods. |
|
Cleansing Methods | It allows you to select the cleansing method to apply to the data fields. |
|
Node Configuration | It allows you to select the instance of the AWS server to provide control over the execution of a task in a workbook or workflow. | For more details, refer to Worker Node Configuration. |
The table below describes the various data cleansing methods and their corresponding sub-methods.
Method | Sub-Method | Description |
|---|---|---|
Remove Unwanted Characters | Remove leading and trailing whitespaces | Remove any extra whitespace(s) before or after a string, word, or number. |
Remove tabs, line breaks, and duplicate whitespaces | Remove any extra tabs, line breaks, or repeated whitespaces in a string. | |
Remove all whitespaces | Remove leading, trailing, in-between or duplicate whitespaces. | |
Remove letters | Remove alphabet(s) from a string or a number | |
Remove numbers | Remove a number(s) from strings or words | |
Remove punctuations | Remove all punctuation marks from strings, words, or numbers | |
Modify Case | Upper Case | Convert all letters or words in a string to upper case. |
Lower Case | Convert all letters or words in a string to lower case. | |
Title Case | Capitalize each word in a phrase or a sentence. | |
Replace Null Data | Replace with blanks (string columns) | Replace any null string value in a cell with a blank space. It renders an empty cell. |
Replace with zero (numeric columns) | Replace any null value in a numerical column with zero (0). | |
Remove Null Data | Remove Null Rows | Remove all rows with a null value in any column |
Only remove rows that have a null value in every column | ||
Remove Null Columns | Remove all columns with a null value in any row | |
Only remove columns that have a null value in every row |
Note: | By default, the following values are interpreted as Not a Number (NaN):
|
Example of Combined Data Cleansing
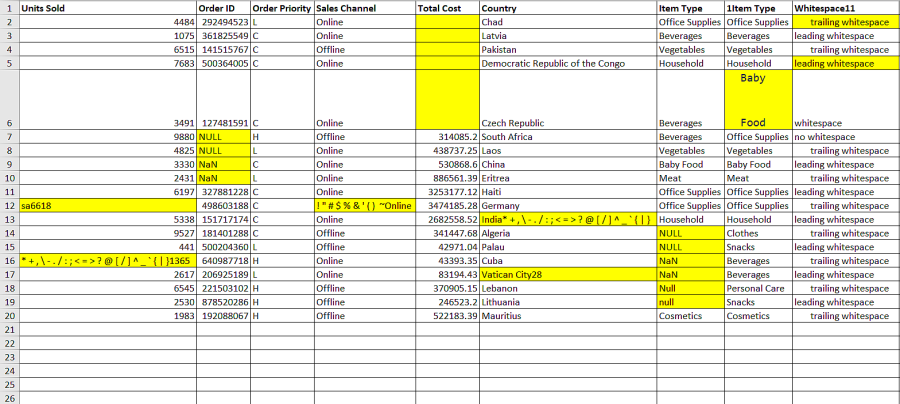
Consider a dataset with multiple irregularities present in various cells.
A snippet of the input data is shown below. The following irregularities are appropriately highlighted as shown.
- Number and Strings with Special Characters
- Empty Cells
- Null Values in Columns
- Line Break between Words
- Leading and Trailing Whitespaces
We apply various Data Cleansing methods to the above data and explore the results. The following scenarios display the effect of the sub-methods.
Method 1: Remove Unwanted Characters
Sub-Method 1: Remove leading and trailing whitespaces
Applied on Column: Whitespace11
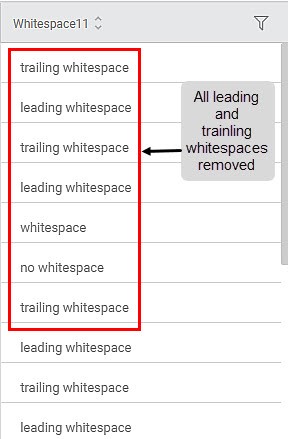
Similarly, you can use the Remove all whitespaces sub-method to remove leading, trailing, in-between, and duplicate whitespaces.
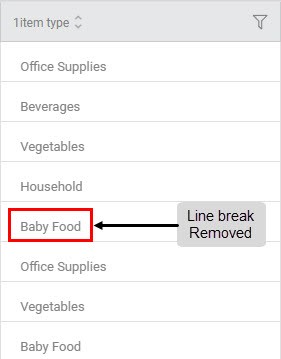
Sub-Method 2: Removing Line Break
Applied On Column: 1Item Type
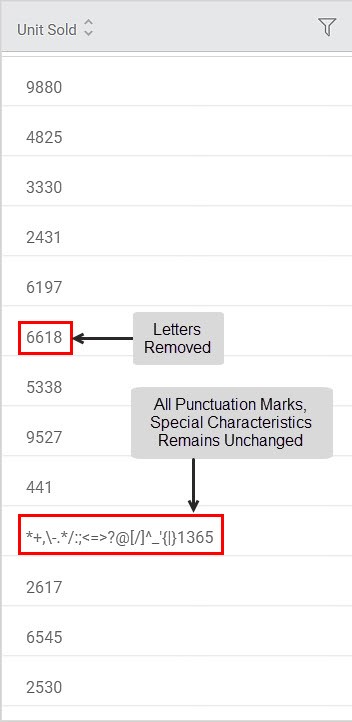
Sub-Method 3: Removing letters
Applied On Column: Units Sold
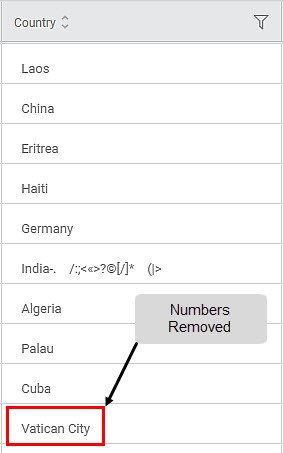
Sub-Method 4: Removing numbers
Applied On Column: Country
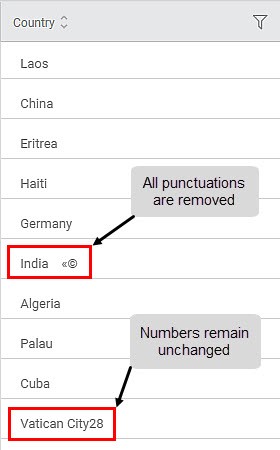
Sub-Method 5: Removing punctuations
Applied On Column: Country
Method 2: Modify Case
Sub-Method 1: Upper Case
Applied to Column: Sales Channel
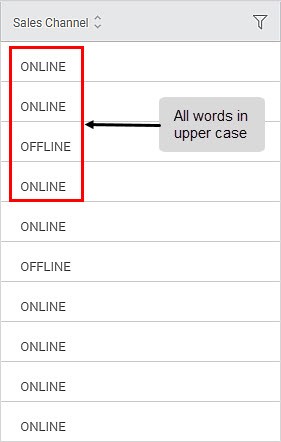
Sub-Method 2: Lower Case
Applied to Column: Sales Channel
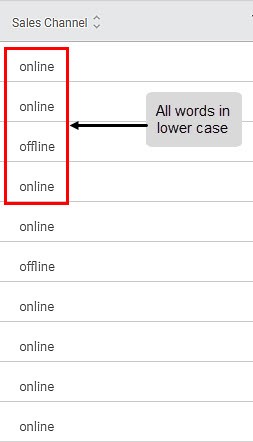
Sub-Method 3: Title Case
Applied to Column: Whitespace11
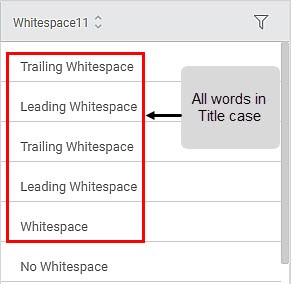
Method 3: Replace Null Data
Sub-Method 1: Replace with blanks (string columns)
Applied to Column: Item Type
![]()
Sub-Method 2: Replace with zero (numeric columns)
Applied to Column: Order ID
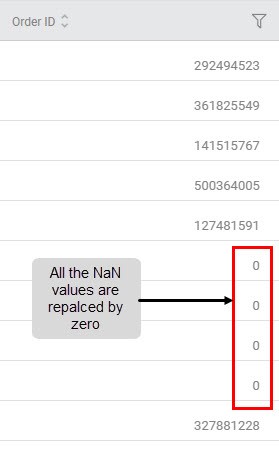
Another snippet of input data shown below contains the following irregularities as appropriately labeled.
- Rows/Columns with NaN Value
- Empty Cells and Cells with Empty Spaces
- Rows and Columns with all NaN and Empty values
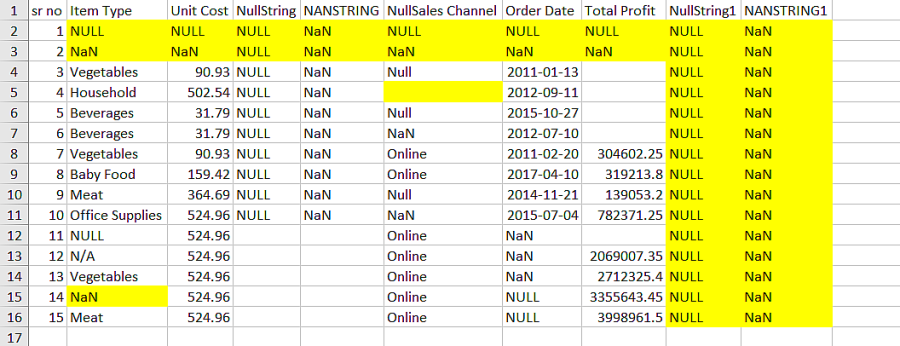
We apply the Remove Null Data method to the above data and explore the results. The following scenarios display the effect of the sub-methods.
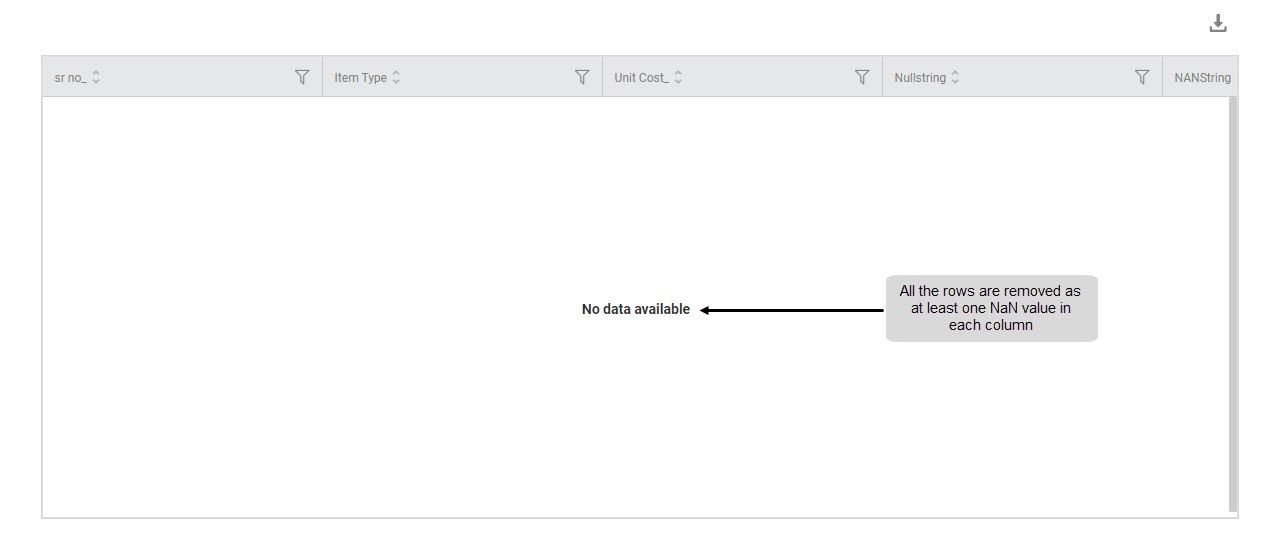
Method 4A: Remove Null Data (Remove Null Rows)
Sub-Method 1: Remove all rows with a null value in any column
Since all columns contain at least one null value, all the rows are deleted.
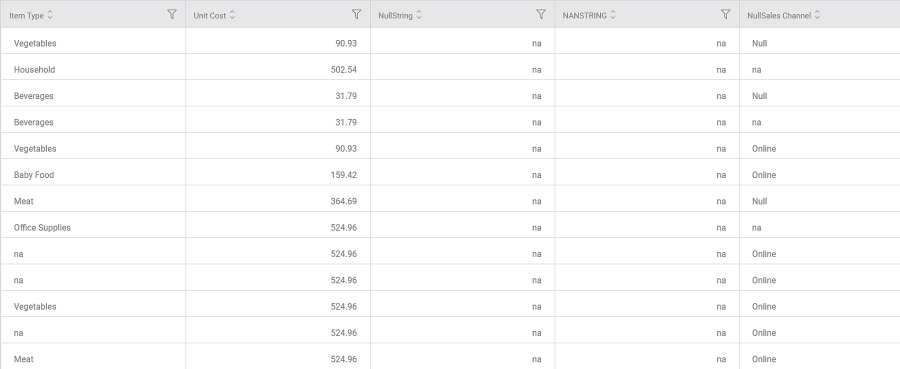
Sub-Method 2: Only remove rows that have a null value in every column
The original data contains fifteen rows of data. Out of these, the first two rows contain a null value in every column.
The image below shows that the first two rows are removed. Hence, only thirteen rows remain in the output.
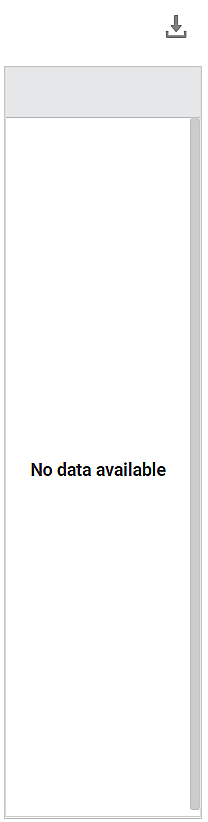
Method 4B: Remove Null Data (Remove Null Columns)
Sub-Method 1: Remove all columns with a null value in any row
Since all rows contain at least one null value, all the columns are deleted.
Sub-Method 2: Only remove columns that have a null value in every row
In the original data, out of the nine columns containing data, four columns, namely NullString, NANSTRING, NullString1, and NANSTRING1 contain null values in every row. They also contain empty cells which are considered NaN values.
The image below shows that the above-mentioned four columns are removed. Hence, only five columns remain in the output.
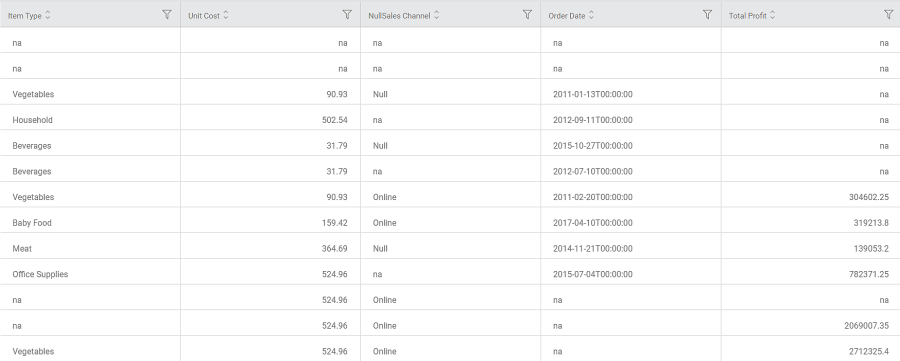
Table of Contents