Working with Batches
Workflow in Data Integrator allows you to divide the dataset into batches and then process it. Batch processing is mainly used to simplify many ETL operations like Missing value Imputation, expression, and validating data. You can specify the batch size called Chunk. Let's take a look at batch processing step by step
Batch Processing Steps
- Click on three dots (
 ) on the right-hand corner of the Data Integrator landing page. The batch processing option is displayed.
) on the right-hand corner of the Data Integrator landing page. The batch processing option is displayed. - Click on batch processing option, and the following popup is displayed
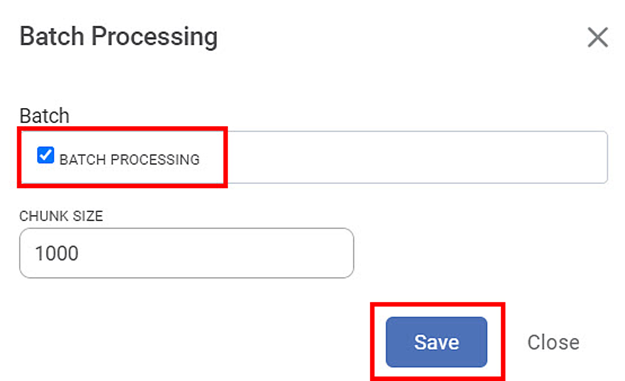
- The default chunk size is 10000. If you remove it and change it to zero, you will get an error message. The batches are created depending on the chunk size.
- The data page will be displayed as follows
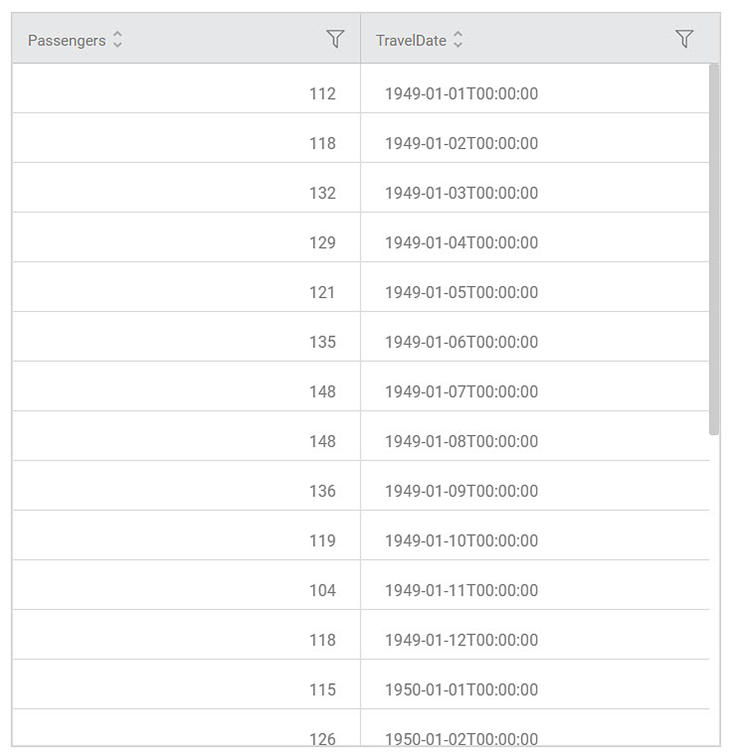
- The records are processed as per mentioned batch size. When you explore the output, you will see all the processed data together. You can view maximum 10000 records per page.
- The pagination is applied when the dataset contains more than 1000 records.
Advantages
- Processing becomes faster. It improves the speed of many ETL operations like Missing value Imputation, expression, Cleansing, and model testing.
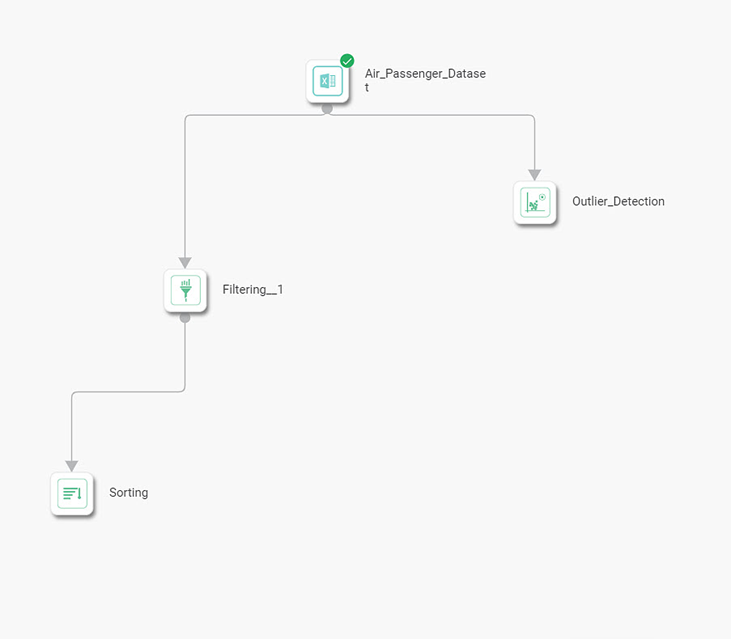
- The parallel processing becomes faster. Consider the following workflow.
- Dataset reads the data from the file.
- You build an expression and save it in the output file in one process.
- In another process you build the Model.
- When you apply batch processing, both processes run concurrently.
- Following figure explains the parallel processing.
- You are allowed to explore the model when it is processing.
Limitations
- Apply Batch processing only on Workflow.
- Don't apply Batch processing in the case of entire column operations like average, and totals.
- Batch processing is not allowed on the datasets generated using the following techniques
- SSAS RDBMS
- JSON file format
- Google news
Table of Contents