Stemmer | |||||
Description | The automated process produces a base string in an attempt to represent related words. | ||||
Why to use | Textual Analysis – Pre Processing | ||||
When to use | When you want to get root form of words for the textual data. It mapping the group of words to the same stem, even if the stem itself is not a valid word in the language. | When not to use | On numerical data. | ||
Prerequisites | It is used on textual data | ||||
Input | Program | Output | program | ||
Predecessor |
| Successor |
| ||
Related algorithms |
| Alternative algorithm | Lemmatizer | ||
Statistical Methods used | - | Limitations | It can often create non-existent words that does not have any meaning. | ||
Stemmer is located under Textual Analysis ( ![]() ) in Pre Processing, in the task pane on the left. Use drag-and-drop method to use algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
) in Pre Processing, in the task pane on the left. Use drag-and-drop method to use algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
Stemming is the process in information retrieval that reduces an inflected or derived word to its stem form or the root word form. It produces a base string to represent related words.
For example, the root word 'run' can represent all other words like 'runs', 'running', 'ran', and other forms of it.
Properties of Stemmer
The available properties of Stemmer are as shown in the figure given below.
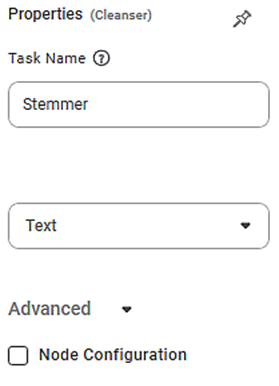
The table given below describes different fields present on properties of stemmer.
Field | Description | Remark | |
|---|---|---|---|
Task Name | It displays the name of the selected task. | You can click the text field to edit or modify the name of the task as required. | |
Text | It allows you to select the text for which you want to map group of words to its root word. |
| |
| Advanced | Node Configuration | It allows you to select the instance of the AWS server to provide control on the execution of a task in a workbook or workflow. | For more details, refer to Worker Node Configuration. |
Interpretation of Stemmer
The figure given below shows the result of Stemmer applied on Google News snippets.
In the figure, the column heading CSTText represents the text after the Stemmer is applied.
In the highlighted example, the words "singer" and "cases" have been reduced by their stems "sing" and "case" respectively.
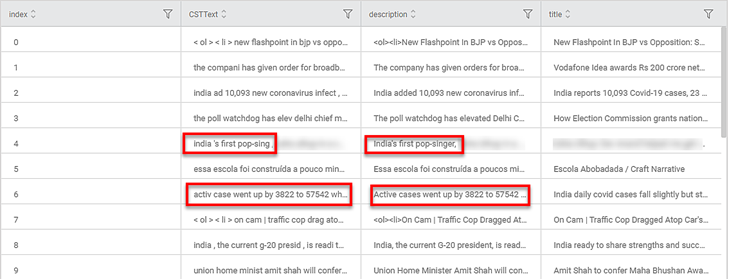
Table of Contents