| TF-IDF | |||
Description | TF-IDF stands for Term Frequency-Inverse Document Frequency. | ||
Why to use | For TF-IDF vectorization of multiple texts in a dictionary. | ||
When to use |
| When not to use | On numerical data. |
Prerequisites |
| ||
Input | Any dataset that contains text data. | Output |
|
Statistical Methods used |
| Limitations | Cannot be used on data other than text data. |
TF-IDF is located under Textual Analysis ( ![]() ) in Text Vectorization, in the task pane on the left. Use the drag-and-drop method (or double-click on the node) to use the algorithm on the canvas. Click the algorithm to view and select different properties for analysis.
) in Text Vectorization, in the task pane on the left. Use the drag-and-drop method (or double-click on the node) to use the algorithm on the canvas. Click the algorithm to view and select different properties for analysis.
Refer to Properties of TF-IDF.
The terms that are useful in understanding TF-IDF are given below.
Term frequency – It represents the number of times a word (term) appears in a dictionary per the number of terms in the dictionary.
Document frequency – It represents the number of times a word appears in a dictionary.
Inverse document frequency – It represents the logarithm of the result of the number texts in a dictionary per the number of texts which contain a word. Thus, if the word is very common and appears in many texts, the value of IDF will approach zero, else it will approach one.
Thus, the TF-IDF score is computed as TF multiplied by IDF. The higher the TF-IDF score of a feature in the dictionary, the more relevant is the word from a text in the dictionary.
Properties of TF-IDF
The available properties of TF-IDF are as shown in the figure given below.
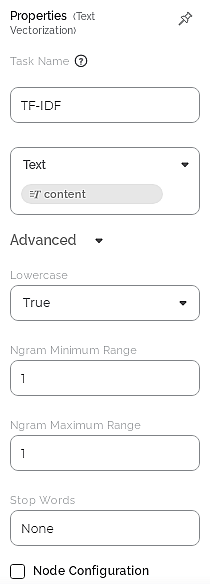
The table given below describes the different fields present on the Properties pane of TF-IDF.
Field | Description | Remark | |
|---|---|---|---|
Task Name | It displays the name of the selected task. | You can click the text field to edit or modify the name of the task as required. | |
Text | It allows you to select the text variable for which you need to perform the task. |
| |
Advanced | Lowercase | It converts the features to lowercase if selected as True. | The default value is True. |
Ngram Minimum Range | It determines the minimum probability of occurrence of each feature in a sequence of N words, where N = 1, 2, 3, and so on. |
| |
Ngram Maximum Range | It determines the maximum probability of occurrence of each feature in a sequence of N words where N = 1, 2, 3, and so on. |
| |
Stop Words | It allows you to add one or multiple stop words from the standard English set of stop words. |
| |
Example of TF-IDF
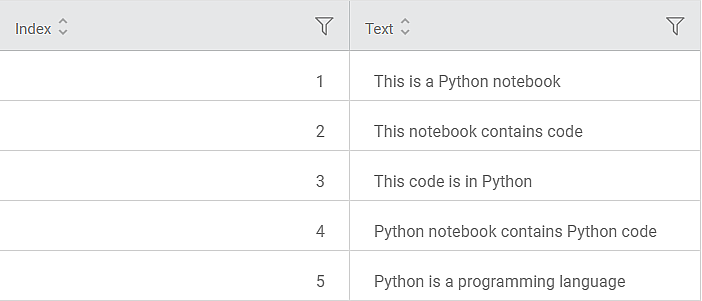
Consider a dataset with one of the variables as a text variable. A snippet of the input data is shown in the figure given below.
In the Properties pane, the values are selected as shown in the table below.
Text | Text |
Lowercase | True |
Ngram Minimum Range | 1 |
Ngram Maximum Range | 1 |
Stop Words | None |
The first part of the Result of TF-IDF is shown in the figure below.
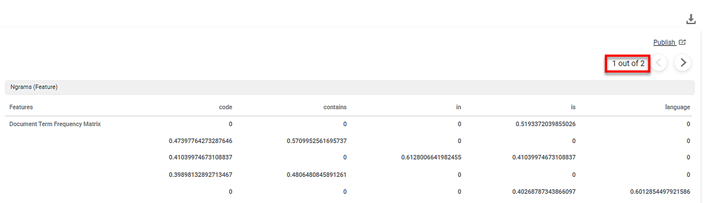
The second part of the Result of TF-IDF is shown in the figure below.
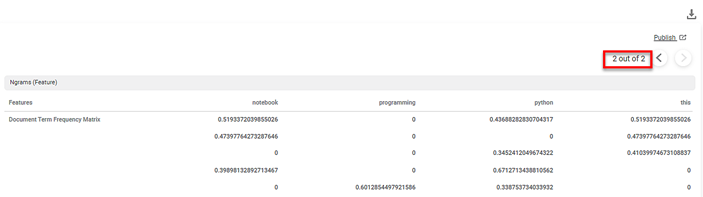
On the Result page,
- The Document Term Frequency Matrix for the selected text variable is displayed.
- In the matrix, each Features column represents each feature in the dictionary.
Key Observations:
- The dictionary (content_Original) contains 9 features.
- Each text is a row in the document term frequency matrix. Thus, the document term frequency matrix has 9 rows.
- The Result page displays five features on each page. For example, code, contains, in, as, and so on.,
- The features in the columns are arranged alphabetically.
- To navigate to the next five features, you can click on the next arrow (
 ) icon, and so on.
) icon, and so on. - Each feature is converted to lowercase since the value selected in the Lowercase drop-down in the Properties pane is True.
- The TF-IDF score of a feature is a non-zero value if the relevance of the feature in a text is more.
- The cell corresponding to the text in the feature column, in which the feature appears the most, displays the non-zero TF-IDF score.
- The cells corresponding to the remaining text rows in the column, in which the feature has very low relevance, display 0.
In the above example, the TF-IDF score of the feature notebook is 0.5193. It appears in only that cell of the text row in which the feature appears most commonly. The other cells in the about feature column display 0. The score is also calculated considering the Ngram Minimum Range and Ngram Maximum Range values entered in the Properties pane. No word is excluded from the features columns since stop words are not defined in the Properties pane.
| If stop words are used, then those mentioned are excluded from the feature columns in the matrix. |
You can click (![]() ) on the TF-IDF task node to publish the model. The model can be reused in a workbook and workflow for training and experimenting or can be used in a workflow for production. For more information on publishing a task, refer to Publishing Models.
) on the TF-IDF task node to publish the model. The model can be reused in a workbook and workflow for training and experimenting or can be used in a workflow for production. For more information on publishing a task, refer to Publishing Models.
The selected text variable (dictionary) contains 5 rows of text data. Each row represents a text in the dictionary. The Data page in the TF-IDF result displays the text variable and its texts. A snippet of the text variable is shown in the figure given below.
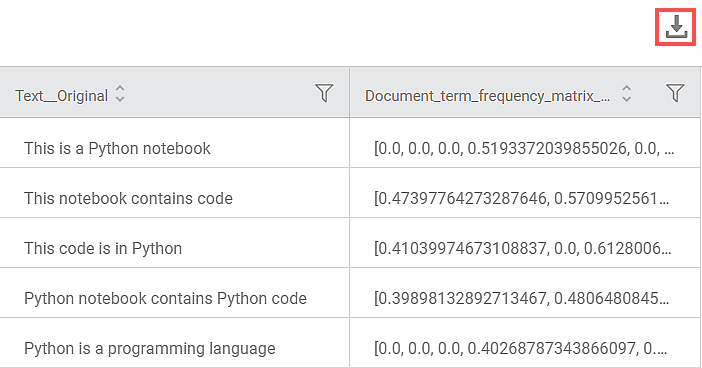
On the Data Page, you can see the
- Text variable column name as <variable name>_Original along with its text in rows.
- Document term Frequency Matrix containing the Term frequency for each feature (according to the alphabetical sequence shown on the Results page) in a row.
- You can download the text data from the Data page using the download icon (
 ).
). - You can hover over a row in the text variable column to view the entire text in that row.
Table of Contents