Word Embedding | |||
|---|---|---|---|
Description |
| ||
Why to use | Machine learning models cannot process text so we need to convert this textual data into numerical data. Hence, we have to use this algorithm. | ||
When to use | When required to represent words or phrases in vector space with several dimensions | When not to use | In applications where antonyms or even synonyms are required to be used. |
Prerequisites | None | ||
Input | One textual column | Output | Vector norm – Higher the frequency of the word, larger is the value of the norm in this word embedding. |
Statistical Methods Used | None | Limitations | Words with multiple meanings are often combined into a single representation. |
Word Embedding is located under Textual Analysis ( ![]() ) in Pre processing on the left task pane. Alternatively, use the search bar for finding the Word Embedding feature. Use the drag-and-drop method or double-click to use the algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
) in Pre processing on the left task pane. Alternatively, use the search bar for finding the Word Embedding feature. Use the drag-and-drop method or double-click to use the algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
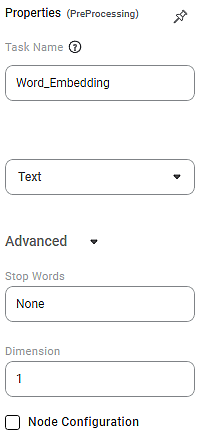
Properties of Word Embedding
The available properties of Word Embedding are shown below.
The table below describes the different properties of the Mann Whitney U Test.
Field | Description | Remark | |
|---|---|---|---|
Task Name | It is the name of the task selected on the workbook canvas. |
| |
Text | It allows you to select one textual column. |
| |
Advanced | Stop words | A dictionary of words that are restricted to use. |
|
Dimension | It represents the total number of features that are encoded in the word embedding. |
| |
Node Configuration | It allows you to select the instance of the AWS server to provide control over the execution of a task in a workbook or workflow. | For more details, refer to Worker Node Configuration. | |
Example of Word embedding
An employee is given the task of converting a specific set of words into machine readable vector form while maintaining that the words that have similar meaning are placed in close spatial capacity. He uses Word Embedding to achieve this.
Below is a snippet of the output data-
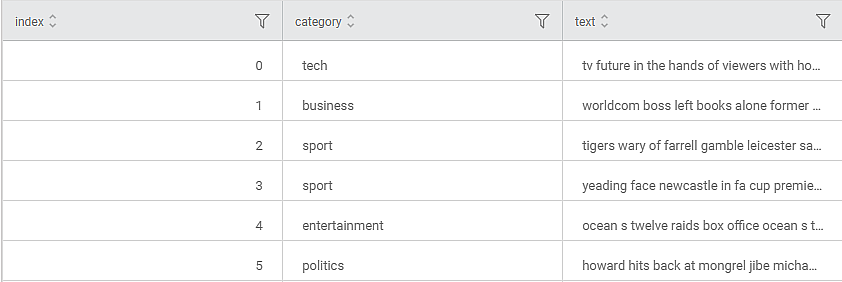
Further, the Result page is as follows.
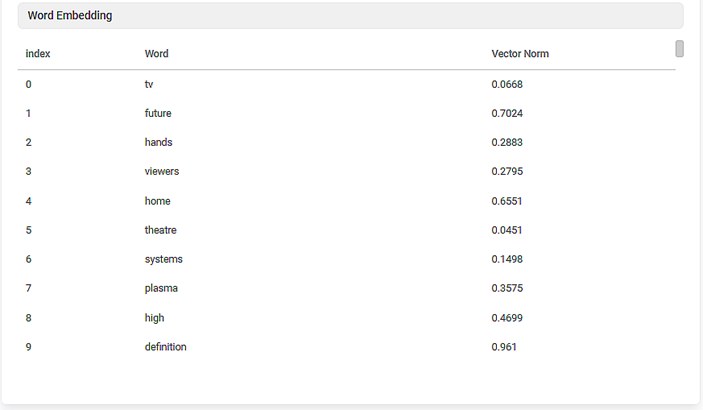
The result page consists of the following sections:
- Index:
This section displays the index. - Word:
This section displays the word categories available in the dataset. - Vector Norm:
- These are the metrics created by using the stop words and the words that are available in the selected data column. They give the vector form for the categories in the dataset.
- The higher the word frequency, the larger is the norm of this word embedding.
- If the words are used in different contexts, the norm of the vector decreases.
Table of Contents