Frequent Words Remover | |||||
Description | Frequent words remover eliminates the frequent word/words before further processing. These words are called as Stop words. | ||||
Why to use | Textual Analysis – Pre Processing | ||||
When to use | When you want to remove stop words from the data. | When not to use | On numerical data. | ||
Prerequisites | It should be textual data. | ||||
Input | Nick likes to play football, however he is not too fond of tennis. | Output | 'Nick', 'likes', 'play', 'football', ',', 'however', 'fond', 'tennis', '.' | ||
Related algorithms |
| Alternative algorithm | - | ||
Statistical Methods used | - | Limitations | It cannot be used on Numerical data. | ||
One of the major tasks of data pre-processing is to filter out useless data. It is also called as text mining. In NLP, useless words are called stop words. Frequent words remover eliminates the frequent word/words before further processing. The output is a text devoid of stop words. This helps you to extract your data as required.
Stop words |
'ourselves', 'hers', 'between', 'yourself', 'but', 'again', 'there', 'about', 'once', 'during', 'out', 'very', 'having', 'with', 'they', 'own', 'an', 'be', 'some', 'for', 'do', 'its', 'yours', 'such', 'into', 'of', 'most', 'itself', 'other', 'off', 'is', 's', 'am', 'or', 'who', 'as', 'from', 'him', 'each', 'the', 'themselves', 'until', 'below', 'are', 'we', 'these', 'your', 'his', 'through', 'don', 'nor', 'me', 'were', 'her', 'more', 'himself', 'this', 'down', 'should', 'our', 'their', 'while', 'above', 'both', 'up', 'to', 'ours', 'had', 'she', 'all', 'no', 'when', 'at', 'any', 'before', 'them', 'same', 'and', 'been', 'have', 'in', 'will', 'on', 'does', 'yourselves', 'then', 'that', 'because', 'what', 'over', 'why', 'so', 'can', 'did', 'not', 'now', 'under', 'he', 'you', 'herself', 'has', 'just', 'where', 'too', 'only', 'myself', 'which', 'those', 'i', 'after', 'few', 'whom', 't', 'being', 'if', 'theirs', 'my', 'against', 'a', 'by', 'doing', 'it', 'how', 'further', 'was', 'here', 'than' |
Frequent Words Remover is located under Textual Analysis ( ![]() ) in Pre Processing, in the task pane on the left. Use drag-and-drop method to use algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
) in Pre Processing, in the task pane on the left. Use drag-and-drop method to use algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
Properties of Frequent Words Remover
The available properties of Frequent Words Remover are as shown in the figure given below.
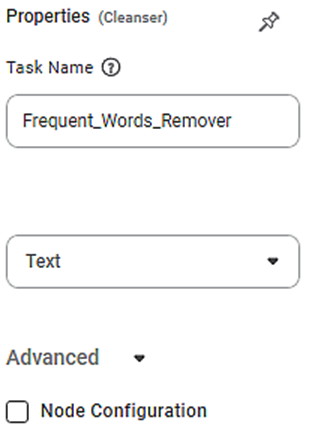
The table given below describes different fields present on properties of frequent words remover.
Field | Description | Remark | |
|---|---|---|---|
Task Name | It displays the name of the selected task. | You can click the text field to edit or modify the name of the task as required. | |
Text | It allows you to select the text from which you want to remove the frequent words. |
| |
| Advanced | Node Configuration | It allows you to select the instance of the AWS server to provide control on the execution of a task in a workbook or workflow. | For more details, refer to Worker Node Configuration. |
Interpretation of Frequent Words Remover
The figure given below shows the result of the Frequent Words Remover.
In the figure, the column heading CFRText represents the text after the Frequent Words Remover has been applied.
In the highlighted example, the Frequent Word "has" is removed.
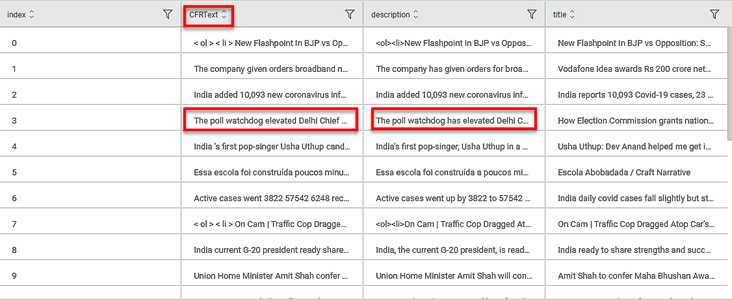
Table of Contents