Connectivity Based Clustering | |||||
Description | Connectivity Based Clustering builds the clusters based on the notion that the vectors of data points in space exhibit more similarity to each other than the data points lying farther away. | ||||
Why to use | To form clusters of textual data. | ||||
When to use | When the number of clusters is not known. | When not to use |
| ||
Prerequisites | Input data should be of text type and should not contain special characters and numbers. | ||||
Input | Textual Data | Output | Data divided into clusters | ||
Statistical Methods used |
| Limitations |
| ||
Connectivity Based Clustering is located under Textual Analysis (![]() ) in Clustering, in the left task pane. Use the drag-and-drop method to use the algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
) in Clustering, in the left task pane. Use the drag-and-drop method to use the algorithm in the canvas. Click the algorithm to view and select different properties for analysis.
Refer to Properties of Connectivity Based Clustering.
Connectivity-based clustering is also called hierarchical clustering because it builds clusters in a hierarchy. In clustering, the data points closer to each other exhibit more similarity than those away from each other.
The algorithm starts with assigning data points to a cluster of their own. Then two nearest clusters are merged to form a single cluster. In the end, the algorithm terminates with only one cluster remaining.
There are two approaches to this model. In the first approach, data points are classified into separate clusters and then aggregated as the distance between them decreases.
In the second approach, data points are distributed into a single large cluster and then segregated as the distance between them increases. Rubiscape uses this approach.
Properties of Connectivity Based Clustering
The available properties of Connectivity Based Clustering are as shown in the figure given below.
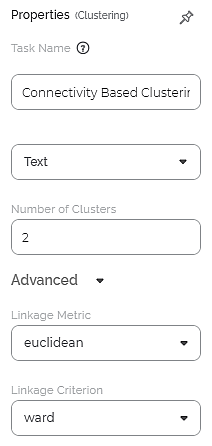
The table given below describes the different fields present on the properties of Connectivity Based Clustering.
Field | Description | Remark | |
Task Name | It is the name of the task selected on the workbook canvas. | You can click the text field to edit or modify the name of the task as required. | |
Text | It allows you to select Independent variables. |
| |
Number of Clusters | It allows you to enter the number of clusters you want to create. | The default value is 8. | |
Advanced | Linkage Metric | It allows you to select the metric used to compute the linkage. |
|
Linkage Criterion | It allows you to select the metric used for the merge strategy. | The available options are –
| |
Example of Connectivity Based Clustering
Consider a dataset of musical instruments review. A snippet of input data is shown in the figure given below.
After using the Connectivity Based Clustering, the following results are displayed.
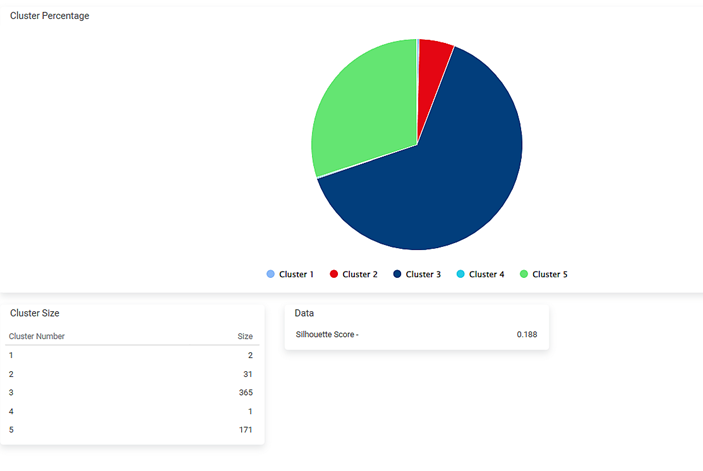
As seen in the above figure, the number of clusters and each cluster's size are displayed along with the Silhouette Score.
Table of Contents